Grid Workers Explained¶
@author: Tomasz Kornuta & Vincent Marois
There are five Grid Workers, i.e. scripts which manage sets of experiments on grids of CPUs/GPUs. These are:
- two Grid Trainers (separate versions for collections of CPUs and GPUs) spanning several trainings in parallel,
- two Grid Testers (similarly),
- a single Grid Analyzer, which collects the results of several trainings & tests in a given experiment directory into a single csv file.
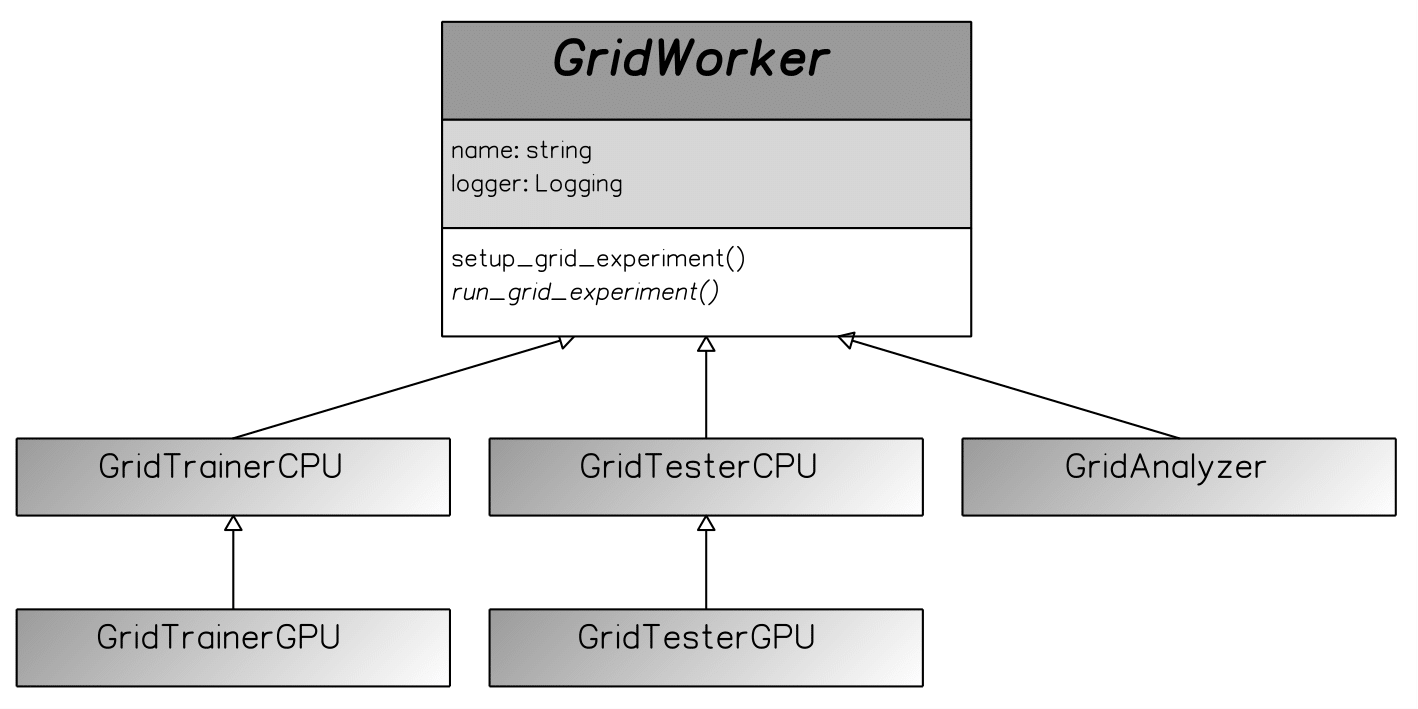
The class inheritance of the grid workers. The Trainers & the Tester classes inherit from a base Worker class, to follow OOP best practices.
The Grid Trainers and Testers in fact spawn several instances of base Trainers and Testers respectively. The CPU & GPU versions execute different operations, i.e. the CPUs grid workers assign one processor for each child, whereas the GPUs ones assigns a single GPU instead.
Fig. 7 presents the most important sections of the grid trainer configuration files. Section grid tasks defines the grid of experiments that need to be executed, reusing the mechanism of default configuration nesting. Additionally, in grid settings, the user needs to define the number of repetitions of each experiment, as well as the maximum number of authorized concurrent runs (which later on will be compared to the number of available CPUs/GPUs). Optionally, the user might overwrite some parameters of a given experiment (in the overwrite section) or all experiments at once (grid_overwrite).
As a result of running these Grid Trainers and Testers, the user ends up with an experiment directory containing several models and statistics collected during several training, validation and test repetitions. The role of the last script, Grid Analyzer, is to iterate through those directories, collecting all statistics and merging them into a single file that facilitates a further analysis of results, the comparison of the models performance, etc.